ML - machine learning



This is just a documentation of my learning progress starting 2018. From 2024 on I created a few subfolders:
2018 - Start with Object Detection
Inspired by object detection for cars with DarkNet (see this TED talk from 2017 by Joseph Redmon) and David’s bachelor work at HCMUTE in connection with a car at the end of 2018 I started to learn more about machine learning.
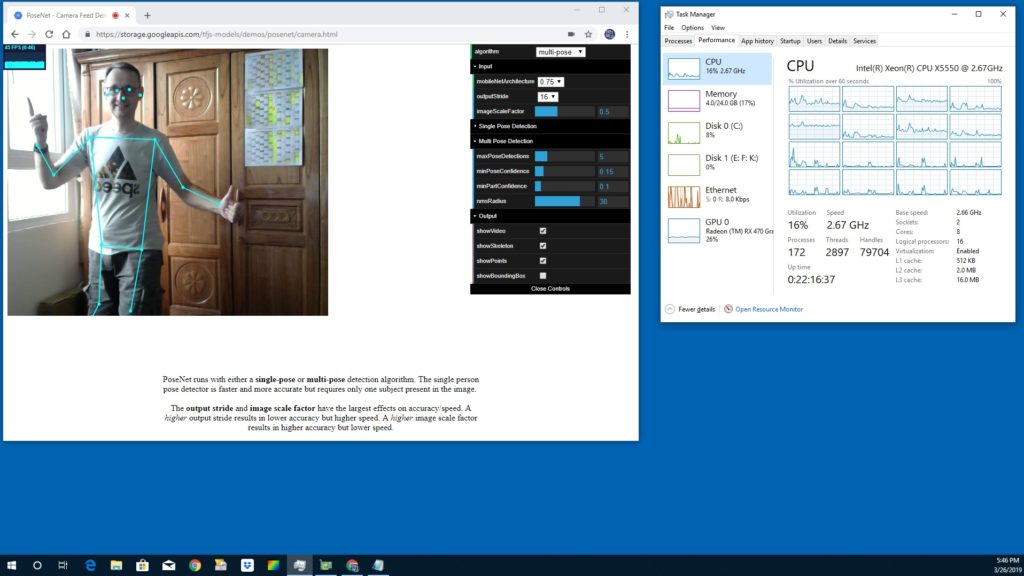
Posenet runs on TensorFlow.lite in a browser on WebGL even on a smartphone. We tested it in December 2018 in Seoul, Korea. In March 2019 I got TensorFlow.js running with my RX470 with 43 fps.
During 2019 NVIDIA announced the Jetson Nano developer kit and with students from AISVN we tried to win one in a competition. Eventually we ordered a package.

Early 2020 some supply chains delay orders, but we finally have the hardware. Now it needs to be combined - and development stalls until 2024.
Facemesh example
![]()

Schedule for 2020
In this article Harsheev Desai describes his journey to become a TensorFlow Developer with Certificate in 5 months.
1. Learn Python
2. Learn Machine Learning Theory
- Coursera Machine Learning on Statistics, Calculus and Linear Algebra
3. Learn Data Science Libraries
Some of these libraries are Pandas (data manipulation and analysis), Numpy (support for multi-dimensional arrays and matrices), Matplotlib (plotting) and Scikitlearn (creating ML models).
4. Deep Learning Theory
5. TensorFlow Certificate
One reason for tensorflow can be seen in this graph regarding popularity on stackoverflow:
![]()

More about the tensorflow certificate here on medium. It was launched in March 2020 but ceased to exist by 2024. The data science hype, once reflected on platforms like towardsdatascience and medium.com has subsided. The focus has shifted to innovations like transformers and ChatGPT, which have been the “hot new thing” since 2022. Nevertheless, I took the opportunity to learn Python, Pandas, NumPy, Matplotlib, Deep Learning, Machine Learning, and Neural Networks along the way. NumPy and Pandas have now surpassed tensorflow and pytorch on stackoverflow.
2022 - Teach ML in Advanced Automation at SSIS in Unit 5

As covered in a SSIS Stories in March 2022 we made great progress in creating our own Neural Network, Training it and then doing interference on them. See also our website.
If you think about possible learning experiences, we tried a few ones with our students:
- Create your own neural network, generate training data, train your model (with loss and test) and then use the trained model (inference). It was part of the SSIS course Advanced Automation https://github.com/ssis-aa/machine-learning
- Image classification: Select training data (for example of seagulls) and train a ML model in xcode on your Mac to properly identify your test set of images. It was part of the SSIS course App Development
- Build your own GPT. A phantastic course by Andrej Karpathy with his nanoGPT model guides you in a 2-hour video to create endless Shakespeare. With Googles offerings inside a Colab Jupyter notebook you can train your model without a GPU just in the cloud for free.
- Run your local LLM. With Meta providing the weights for their llama model with 8b, 70b and 405b parameter it is possible in 2024 to run a LLM on your local CPU or GPU. OF course there are some limitations in speed and VRAM size, but that’s part of the learning. Ollama is a good starting point.
- Update your local LLM with RAG (Retrieval Augmented Generation) with links to your documents in
open-webui/backend/data/docs
2024 - start with LLMs
Andrej Karpathy offers a step-by-step guide to build your own Generative Pre-trained Transformer (GPT) starting with 1,000,000 characters from Shakespeare that you can train on your own GPU. Well, at least if it supports CUDA >7.0, otherwise the triton compiler throws an error (like on my slightly older GTX 960):
torch._dynamo.exc.BackendCompilerFailed: backend='inductor' raised:
RuntimeError: Found NVIDIA GeForce GTX 960 which is too old to be supported by the triton GPU compiler, which is used
as the backend. Triton only supports devices of CUDA Capability >= 7.0, but your device is of CUDA capability 5.2
Let’s see what I have and what CUDA Compute Capabilities (CC) these support:
| GPU name | Cores | CC | at | architecture | RAM GB |
|---|---|---|---|---|---|
| Quadro FX 580 | 32 | 1.1 | hp Z600 | Tesla (2006) | 0.5 |
| GTX 650 | 384 | 3.0 | E3-1226 v3 | Kepler (2012) | 1 |
| GT 750M | 384 | 3.0 | MBPr15 2014 | Kepler (2012) | 0.5 |
| M1000M | 512 | 5.0 | Zbook 15 G3 | Kepler (2012) | 1 |
| GTX 960 | 1024 | 5.2 | E5-2696 v3 | Maxwell (2014) | 2 |
| Jetson Nano | 128 | 5.3 | Maxwell (2014) | 4 | |
| GTX 1060 | 1280 | 6.1 | i3-6100 | Pascal (2016) | 6 |
| P104-100 | 1920 | 6.1 | i3-6100 | Pascal (2016) | 8 |
| T4 | 2560 | 7.5 | Google Colab | Turing (2018) | 16 |
| RTX 2080 Ti | 4352 | 7.5 | i5-7600K | Turing (2018) | 11 |
| RTX 3060 Ti | 4864 | 8.6 | i7-8700 | Ampere (2020) | 8 |
| RTX 3070 Ti | 6144 | 8.6 | i3-10100 | Ampere (2020) | 8 |
Only two of 8 are supported by the Triton GPU compiler. How about a newer GPU? At least I can use the T4 in Google’s colaboratory for free. The training takes one hour. And you get two hours for free. Ollama only needs CUDA Compute Capability 5.0 and can therefore run on 5 of my graphic cards. Plus the RX 6600 with ROCm and a hack.
Triton Compatibility (supported hardware):
- NVIDIA GPUs (Compute Capability 7.0+)
- AMD GPUs (ROCm 5.2+)
- Under development: CPUs
My AMD RX 470, RX 580 and RX 6600 are too old to be supported by ROCm, even though the 6600 already uses RNDA2. The RX 6600 can be used if the llvm target is overwritten to be gfx1030 instead of gfx1032. The ROCm installation needs 30 GB! In this regard it seems Nvidia has been ahead of the game for some time now with their proprietary CUDA since 2007. Support for the first Tesla GPUs with Compute Capability 1.1 was only dropped with CUDA SDK 7.0 in 2016. For the current CUDA SDK 12.0 (since 2022) a CC of 5.0 (Maxwell and newer since 2014) is required. That’s true for ollama, too. In 2024 that’s 10 year old hardware.
2025 Legacy status for 5.0 Maxwell, 6.0 Pascal and 7.0 Volta
With the release of the Blackwell GPUs of the GeForce RTX 50 series early 2025 a new version of the SDK was released with version CUDA 12.8. Under 1.5.1 Deprecated Architectures it states: Architecture support for Maxwell, Pascal, and Volta is considered feature-complete and will be frozen in an upcoming release. Found on phoronix.com 2025-01-24.

It looks like Turing is still new enough to receive more updates and features with Compute Capability 7.5 since the new Ray-Tracing (RT) cores are included. This is found in GeForce 16 series and GeForce 20 series. Another rationale could be the GSP (GPU System Processor) that is supported since driver 510 and integrated in the 20 series onward, while initially only used for enterprise solutions.
Inference on local hardware
Early 2023: MacBook Pro M1 with 8GB RAM
In early 2023 I ran a 8b parameter model with a 4 bit quantization on my MacBook Pro at SSIS. It was impressive to see what’s possible with just 8GB of RAM on a laptop!
Early 2024: Workstation with E5-2696v3 18C/36T and 128 GB ECC RAM
It became obvious that you need more RAM for larger models, so I built a new workstation with 128 GB RAM and a 18-core E5-2696 v3 CPU in early 2024. Well, it became another learning experience:
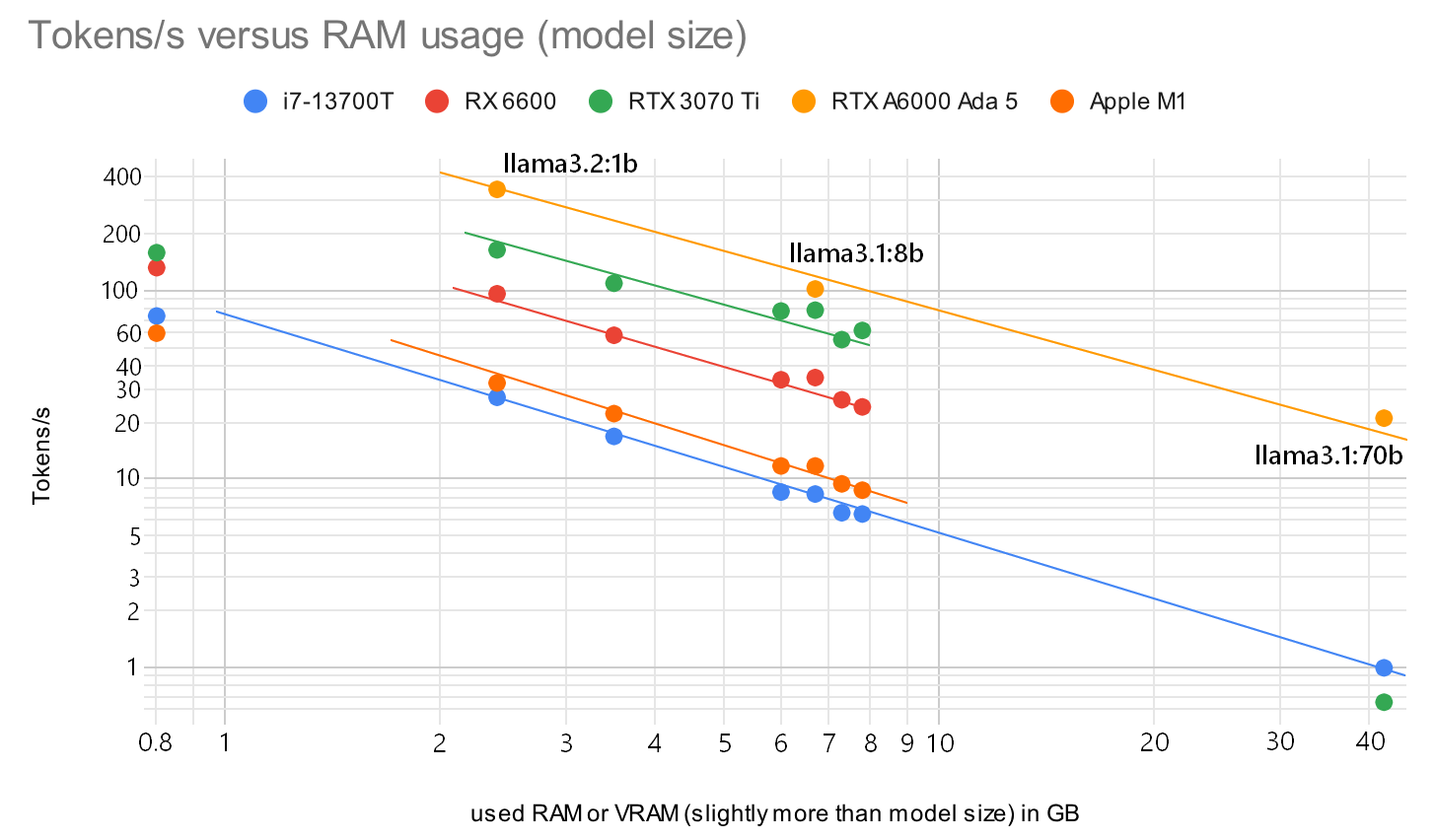
Turns out that the token creation rate is inversely proportional to the size of the model! Or the time to create a token for the answer (TG) is proportional to the RAM speed. A large model might fit into your RAM or VRAM, but the larger the model, the slower an answer will be. The above graph has quantization int4 to fp16, yet the speed for TG is not related to the number of parameters or speed of the GPU, but the model size in RAM - at least for TG. Not a new insight, on llama.cpp there are conversations and graphs related to this topic and Apple hardware. No wonder I get only 0.2 tokens/s for the larger 70b parameter if only using DDR3 ECC RAM. And that 4-bit quantized models are almost as precise as the full fp16 ones was tested in a paper 2023-02-28 (The case for 4-bit precision: k-bit Inference Scaling Laws). With a quarter the size you could fit a model with 4x the parameters in RAM, or get the same model to work 4x faster. Since RAM size and RAM speed are both expensive.
I found 20 tokens/s and faster to be a usable speed to use an LLM, and looking at the graph you see what hardware you will need. CPUs are out of the question. Both RX 6600 and RTX 3060 Ti have 8GB of RAM. I got the RX 6600 for $130 and the RTX 3060 Ti for $200. To get the same tokens/s that I have with 8b models, but for a 70b model I would need a RTX 6000 Ada with 48 GB of RAM for $6000. And even that is by far not enough for a 405b model. Yet the possible accuracy would be nice:
Measurements above are done by Meta.
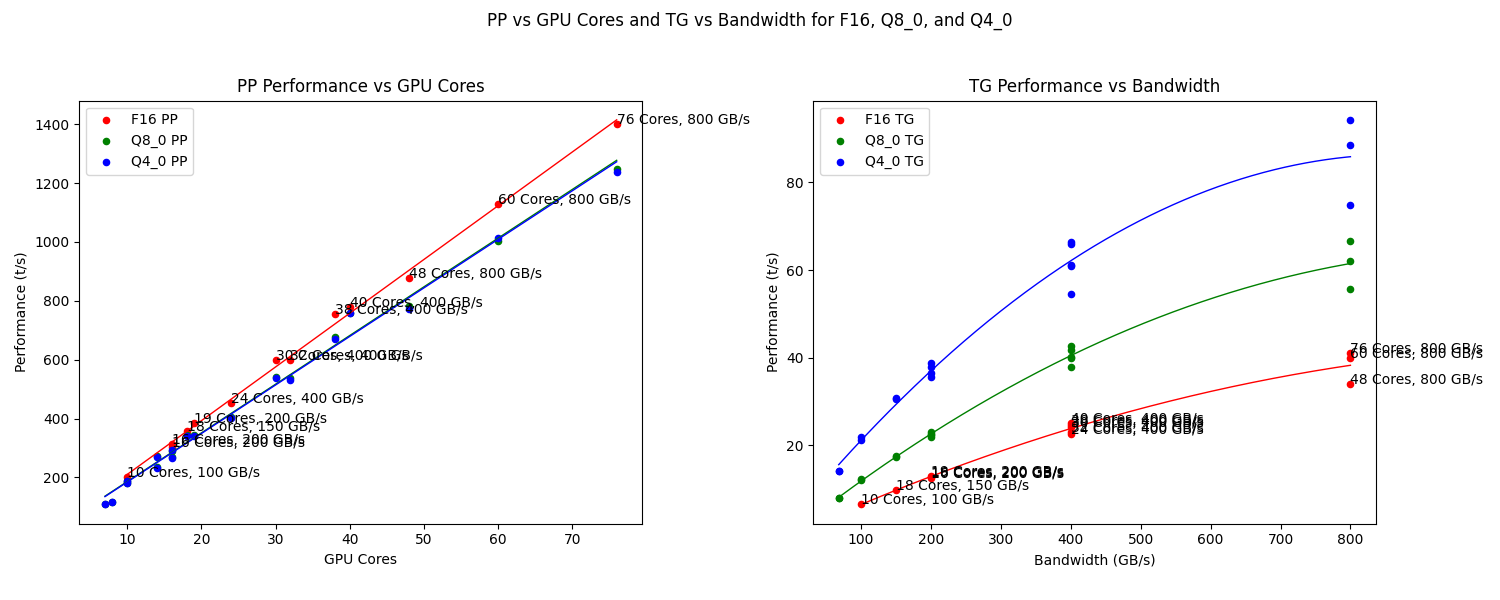
Correlation Model Size and TG token generation - October 2024
After some test runs with ollama in October 2024, reading documentation and the results of other people running tests it seems like there is a simple relationship for the token generation speed $T$ from the RAM bandwidth $B$ in GB/s and the model size $M$ in RAM in GB. I found an almost linear fit with a factor of 1.1, here simplified to 1:
![]()
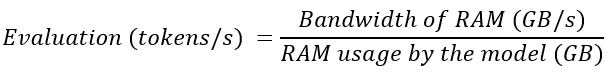
This approximated linear relation can be seen in the Apple Silicon graph in the last paragraph, but it seems to be not linear above 400 GB/s. My experiments show an almost linear relationship, if you convert token/s back to time per token:
What’s with the M CPUs from Apple? Anandtech tested the memory bandwidth for the Ultra CPU and found that the CPU can’t use all the memory bandwidth (M1 128bit wide, M2 Pro 256 bit wide, M4 Max 512 bit wide, M2 Ultra 1024 bit wide). Maybe the reason is that the 8 LPDDR5 128bit controller have to move the data across the chip to the GPU in some instances. Here is a die picture just from the M1 Max chip, see how much area is used just for the memory controllers:
![]()

The two M1 Max chips that are connected with some 10000 traces on the 2.5D chip packaging interposer for 2.5 TB/s bandwidth. This should be enough for the “just” 0.8 TB/s memory bandwidth, but maybe it’s not always as aligned as wanted, or a better driver would improve speed there. So that the GPU cores have their dedicated RAM segment to work on and little data has to be moved over the UltraFusion interface. Anandtech wrote about this technology in 2022. Another test in 2023 only saw 240 GB/s for the M2 Ultra - limit for the CPU? Anyway, here my findings for memory speed in a table:
| CPU | Memory | GByte/s |
|---|---|---|
| E3-1226 v3 | DDR3 1333 | 22 |
| i7-8700 | DDR4 2666 | 35 |
| i7-13700T | DDR4 3200 128bit | 43 |
| Apple M1 | LPDDR4X 4266 | 66 |
| M3 Max | LPDDR5 6400 512bit | 409 |
| M4 Max | LPDDR5X 8533 | 546 |
| GPU | Memory | GByte/s |
|---|---|---|
| Jetson Nano | 4GB LPDDR4 64bit | 25 |
| Quadro M1000M | 2GB GDDR5 128bit | 80 |
| P106-100 | 6GB GDDR5 192bit | 192 |
| P104-100 | 8 GB DDR5X 256bit | 320 |
| RTX 3070 Ti | 8 GB GDDR6X 256bit | 608 |
| P100 | 16 GB HBM2 4096bit | 732 |
| RTX 6000 Ada | 48 GB GDDR6 384bit | 960 |
And while news to me, this very limit of the response time in LLMs is long known in the industry. And there are some novel ideas on how to circumvent the “latency bottleneck”.
Faster inference with speculative execution
Just reading the process and analyzing my findings this approach seems obvious. For one token the entire model has to be loaded from the VRAM into the cache of the GPU and processed. But most of the time the GPU is just waiting for new data to arrive. If we had a good guess for the next token, we could process the extended prompt at the same time with no measurable increased time to generate a token, but we would have 2 tokens generated! Here are some papers about this:
- Accelerating Large Language Model Decoding with Speculative Sampling, paper by DeepMind, 2023/02/02
- Cascade Speculative Drafting for Even Faster LLM Inference, Ziyi Chen at University of Illinois, 2024/02/27
- Speculative Decoding — Make LLM Inference Faster Improve LLM inference speed by 2–3X without degrading any accuracy, Luv Bansal on medium.com, 2024/04/08
- Beyond the Speculative Game: A Survey of Speculative Execution in Large Language Models, Beijing Institute of Technology, China, 2024/04/23
- Async/parallel speculative execution with llama.cpp, okuvshvnov, 2024/04/24
- SpecExec: Massively Parallel Speculative Decoding for Interactive LLM Inference on Consumer Devices, article on together.ai, 2024-06-18
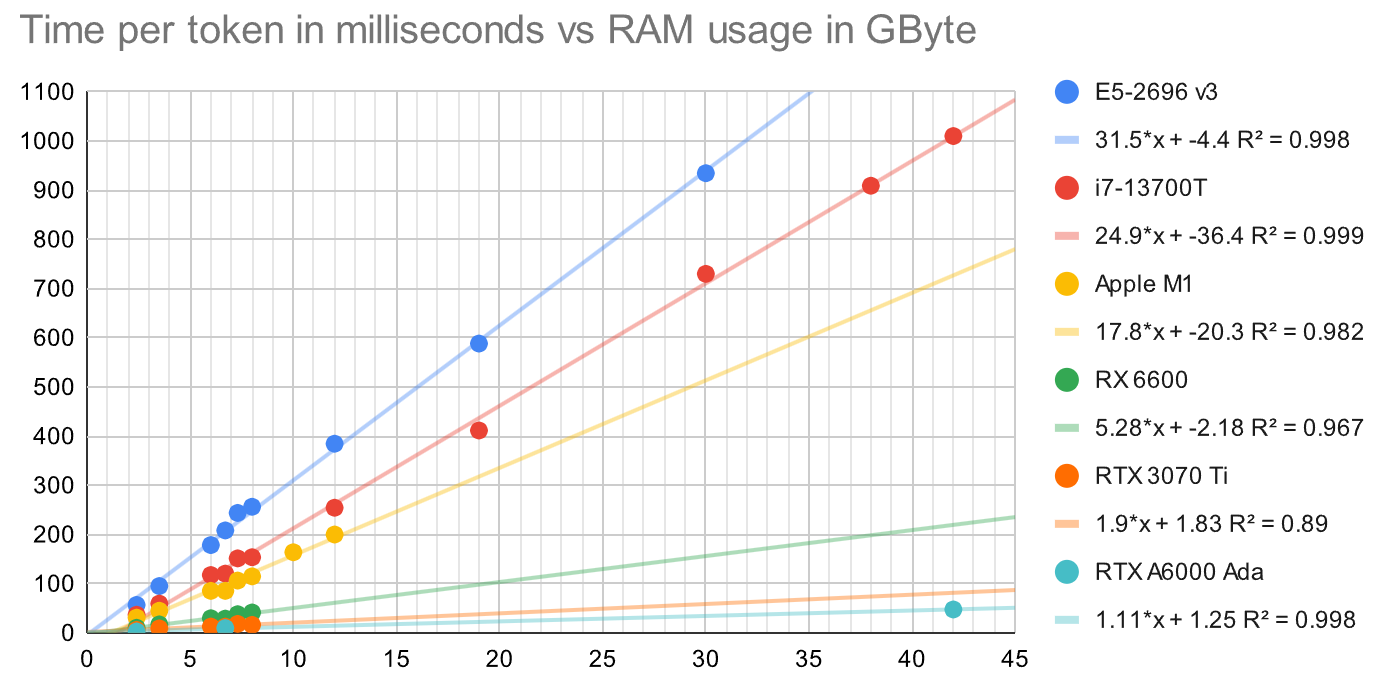
The above papers indicate that 2x or even 3x would be possible. I think you need very good conditions to achive that result - but from a probablility standpoint. One factor is that the speculation of further token takes up a considerable amount of time, and you want it to be fast (and small). On the other hand you want to have a high success rate. I played around with some parameters in a Google Sheet and set the success rate to 90% and made the speculative model 20x faster/smaller. In this case the large model produces a token every 100ms, and the speculative model every 5 ms. Here is the result:
![]()
I can’t get to 2x with these values. I would need a much smaller model that is 50x smaller/faster than the large model to hit 2.37x.
Early 2025: Multi GPU machine for fast Inference
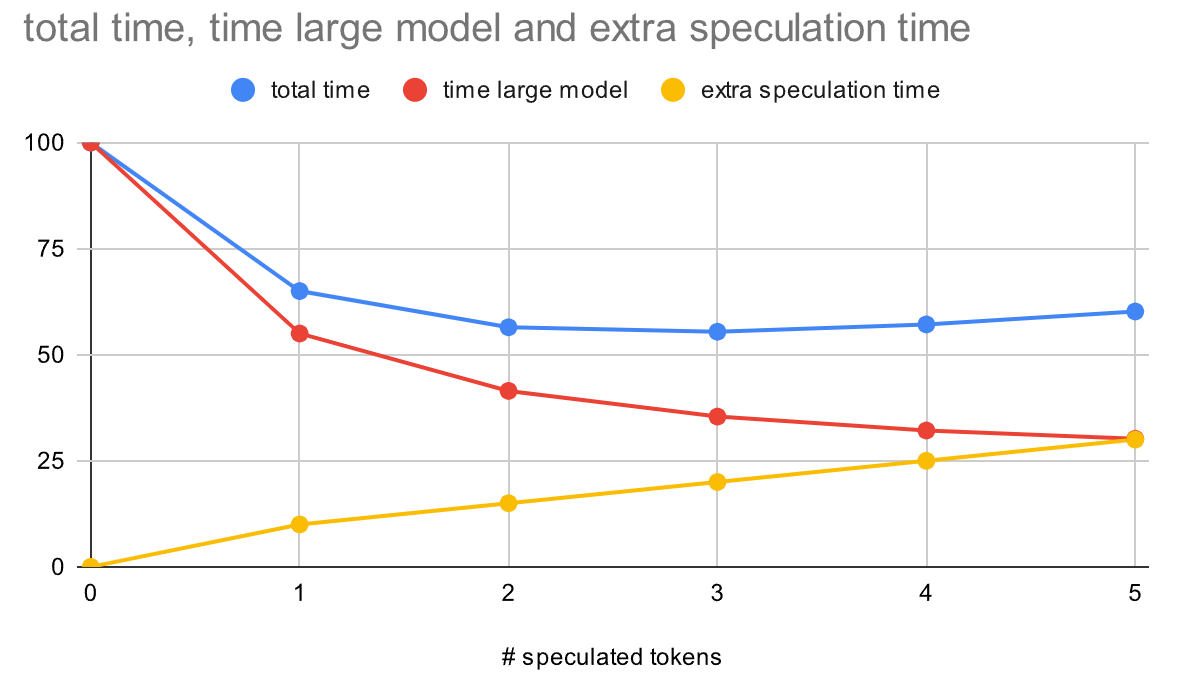
After learning in October 2024 that I not only need a lot of RAM, but it also needs to be fast - preferably VRAM - I frankensteined a damaged EVGA Z170 mainboard together with a cheap i3-6100 CPU and four graphics cards (plus one integrated) for a penta-GPU server:

Summer 2025: Training with unsloth and Triton on Ampere GPU on dedicated server
The machine is a i7-8700 with a RTX 3060 Ti. With only 8GB VRAM we are limited to smaller models, but with unsloth.ai we can offload many layers and make better use of the system RAM.
Improved performance of LLMs in just 1.5 years
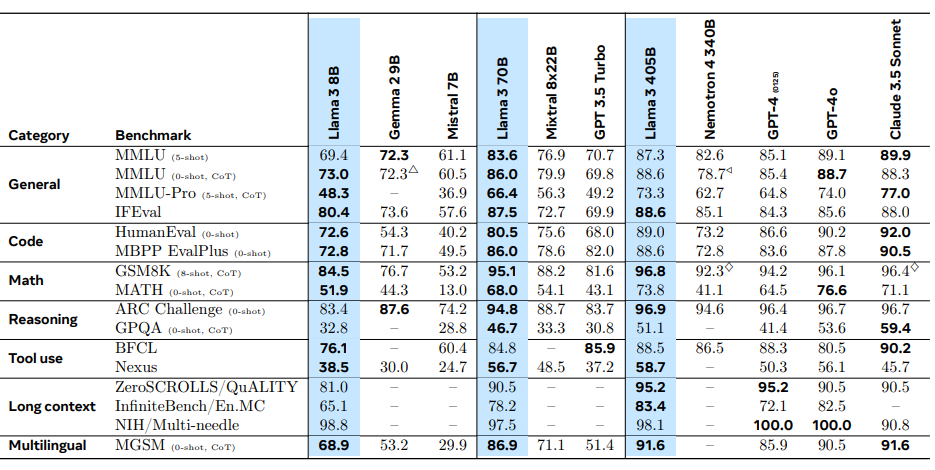
With the open source model Deepseek R1 published early 2025 the gap between closed source and open source models became narrower again. epoch.ai has some interactive graphs, for example the following one for the GPQA Diamond questions.

The article How Far Behind Are Open Models? explores this topic further in detail, for example in benchmarks like GPQA,
It seems that the use of GPUs with AlexNet in 2014 changed the speed of development (and willingness to deploy resources) significantly (from notable AI models):

For comparison my experience, taken from my benchmark repository. FLOPS only $10^9$ to $10^{14}$, equal to $10^{16}$ to $10^{21}$ when running for 115 days (4 months).

Combined:

Slow LLM server in a container
Let’s hope this Mermaid diagram is shown on the webpage:
graph TD
subgraph Hardware [Physical Layer]
A[HP EliteDesk 800 G4 Mini<br/>i5-8500T - RAM - NVMe]
end
subgraph Hypervisor [Virtualization Layer]
B[Proxmox VE]
end
subgraph VM [Virtual Machine]
C[Ubuntu 24.04.3 LTS]
subgraph Runtime [Container Engine]
D[Docker / Docker Compose]
subgraph Containers [Application Layer]
E1[Traefik]
E2[WordPress]
E3[Ollama]
E4[Open WebUI]
E5[Grafana]
E6[Home Assistant]
end
end
end
A --> B
B --> C
C --> D
D --> E1
D --> E2
D --> E3
D --> E4
D --> E5
D --> E6
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333,stroke-width:2px
style C fill:#dfd,stroke:#333,stroke-width:2px
style D fill:#ffd,stroke:#333,stroke-width:2px
Lessons learned so far
- 2023/03/05 Larger models are better, you need more RAM. More expensive.
- 2024/07/10 Faster GPUs generate the tokens faster. Faster means more expensive.
- 2024/07/20 You need newer GPUs. At least Maxwell (CUDA Compute Capability 5.0) for inference with ollama. You need at least Volta (Cuda CC 7.0) to run the Triniton compiler if you build your own nanoGPT. The newer, the more expensive.
- 2024/10/05 It’s actually the memory speed. Faster GPUs in general also have faster memory access. Only for the first PP (prompt processing) stage you need raw GPU power, after that in TG (token generation) or EV (evaluation) it is mainly RAM bandwidth. And again, faster RAM is more expensive.
- 2024/11/10 Finally a reason to have more VRAM for the GPU and really fast memory. For smartphones: To use AI you need more memory. Flagships in Android had a lot of RAM compared to Apples offerings, but no convincing use case. With AI its capacity and speed! And in a way Apple was prepared for years with how the M1 was designed. Now all phones have 8 GB RAM.
- 2024/11/25 Speculative execution could speed up things.
- 2025/02/20 I’ve been using quantized models for years now. But there are different type of layers that react differently to quantization, and are unique in their dimension. More in the Visual Guide to Quantization from Maarten Grootendorst. Including GPTQ and GGUF.
- 2025/05/01 MoE will speed up things! Since only a fraction of the model needs to be processed with the context, the speedup could be in the range of the number of experts. Llama 4 Scout has 16 experts, only 17B active parameters of the 109B total parameters are active at one given time. That’s 6.4x. Unfortunately the whole model needs to be in VRAM - 65.6GB for Q4_K_XL from unsloth. My quad-gpu server has only 24 GB VRAM. And Llama 4 Maverick with 128 experts would even need 243GB with Q4_K_XL (4.5bit). BF16: 801GB. At least theoretically 23x faster. Selective loading to VRAM from SSD? math. And one day later IBM releases Granite 4.0 - combining MoE with Mamba (6S) and other details!
- 2026/03/06 MoE makes CPU systems ore usable and my Penta-GPU server with 30 GB run 30B models efficiently. Even my old HP Z600 with Dual-Xeon X5550 and 24 GB DDR3 can run lfm2:24b with 14GB VRAM and 5 t/s. Dual P104-100 gets __ t/s for “Explain the french revolution in 1000 words”
History
- October 2018 Successful installed darknet on ubuntu, object detection works for stills. Don’t have a webcam, and the video does not work yet.
- December 2018 TensorFlow.lite in a browser on my iPhone 7 runs at 6 fps, demonstrated in Seoul
- March 2019 posenet runs in the browser with new RX470 with 43 fps
- December 2019 On hackster.io starts a new competition AI at the Edge Challenge where you can win a Jetson Nano. I apply and eventually just buy one from arrow
- February 2020 The Jetson car is purchased, Wifi module and 7” display as well. Needs completion - without students due to COVID-19
- July 2024 Reactivated the https://kreier.github.io/jetson-car/ project. The hardware is from 2019 (NVIDIA) but the software is still Ubuntu 18.04 LTS. Updates brake simple things like
makeandgcc. - August 2024 Started to work on https://kreier.github.io/nano-gpt/ to learn more about LLMs, following Andrej Karpathy’s project https://github.com/karpathy/nanogpt
- December 2024 Local Proxmox server with i7-8700 and RTX 3060 Ti running llama3.1:8b in ollama over open-webui and tailscale
- January 2025 Compiled llama.cpp on some of my machines. Later included support to download from huggingface, and CUDA support.
- February 2025 Finished the multi-GPU LLM machine. Now needs more software models to run on, and Grafana visualization of the utilization.
- January 2026 The multi-GPU LLM machine is finally working. Down to just 3 GPUs with a total of 22 GB VRAM it is ok for translategemma 27b and glm-4.7-flash 30B over Open WebUI